|
For the latest stable version, please use Emilua API 0.12! |
Linux namespaces
Emilua provides support for creating actors in isolated processes using Linux namespaces. The idea is to prevent potentially exploitable code from accessing resources beyond what has been explicitly handed to them. That’s the basis for capability-based security systems, and it maps pretty well to APIs implementing the actor model such as Emilua.
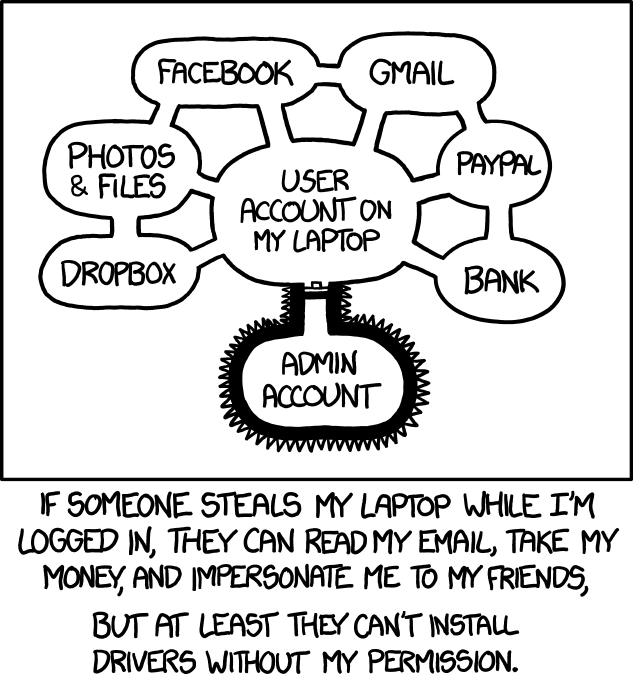
Even modern operating systems are still somehow rooted in an age where we didn’t know how to properly partition computer resources adequately to user needs keeping a design focused on practical and conscious security. Several solutions are stacked together to somehow fill this gap and they usually work for most of the applications, but that’s not all of them.
Consider the web browser. There is an active movement that try to push for a future where only the web browser exists and users will handle all of their communications, store & share their photos, book hotels & tickets, check their medical history, manage their banking accounts, and much more… all without ever leaving the browser. In such scenario, any protection offered by the OS to protect programs from each other is rendered useless! Only a single program exists. If a hacker exploits the right vulnerability, all of the user’s data will be stolen.
The browser is part of a special class of programs. The browser is a shell. A shell is any interface that acts as a layer between the user and the world. The web browser is the shell for the www world. Www browser or not, any shell will face similar problems and has to be consciously designed to safely isolate contexts that distrust each other. I’m not aware of anything better than FreeBSD’s Capsicum to do just this. In the absence of Capsicum, we have Linux namespaces which can be used to build something close (and that’s what browsers use).
Unfortunately the cost for building such sandboxes is too high, and require specialized teams of experts. Emilua attempts to democratize this technology by hiding it behind simple APIs. Right now the API is very crude indeed, but the support will only improve in future releases.
The API
Compartmentalised application development is, of necessity, distributed application development, with software components running in different processes and communicating via message passing.
Robert N. M. Watson, Jonathan Anderson, Ben Laurie, and Kris Kennaway
The Emilua’s API to spawn an actor lies within the reach of a simple function call:
local my_channel = spawn_vm(module)Check the manual elsewhere to understand the details. As for Linux namespaces, the idea is to spawn an actor where no system resources are available (e.g. the filesystem is empty, no network interfaces are available, no PIDs from other processes can be seen, global wide IPC has been unshared, …).
Consider the hypothetical sandbox class:
local mysandbox1 = sandbox.new()
local my_channel = spawn_vm(module, mysandbox1:context())
mysandbox1:handshake()That would be the ideal we’re pursuing. Nothing other than 2 extra lines of code at most under your application. All complexity for creating sandboxes taken care of by specialized teams of security experts. The Capsicum paper[1] released in 2010 analysed and compared different sandboxing technologies and showed some interesting figures. Consider the following figure that we reproduce here:
| Operating system | Model | Line count | Description |
|---|---|---|---|
Windows |
ACLs |
22350 |
Windows ACLs and SIDs |
Linux |
|
605 |
|
Mac OS X |
Seatbelt |
560 |
Path-based MAC sandbox |
Linux |
SELinux |
200 |
Restricted sandbox type enforcement domain |
Linux |
|
11301 |
|
FreeBSD |
Capsicum |
100 |
Capsicum sandboxing using |
Do notice that line count is not the only metric of interest. The original paper accompanies a very interesting discussion detailing applicability, risks, and levels of security offered by each approach. Just a few years after the paper was released, user namespaces was merged to Linux and yet a new option for sandboxing is now available. Within this discussion, we can discard most of the approaches — DAC-based, MAC-based, or too intrusive to be even possible to abstract away as a reusable component — as inadequate to our endeavour.
Out of them, Capsicum wins hands down. It’s just as capable to isolate parts of an application, but with much less chance to error (for the Chromium patchset, it was just 100 lines of extra C code after all). Unfortunately, Capsicum is not available in every modern OS.
Do keep in mind that this is code written by experts in their own fields, and their salary is nothing less than what Google can afford. 11301 lines of code written by a team of Google engineers for a lifetime project such as Google Chromium is not an investment that any project can afford. That’s what the democratization of sandboxing technology needs to do so even small projects can afford them. That’s why it’s important to use sound models that are easy to analyse such as capability-based security systems. That’s why it’s important to offer an API that only adds two extra lines of code to your application. That’s the only way to democratize access to such technology.
| Rust programmers' vision of security is to rewrite the world in Rust, a rather unfeasible undertaking, and a huge waste of resources. In a similar fashion, Deno was released to exploit v8 as the basis for its sandboxing features (now they expect the world to be rewritten in TypeScript). The heart of Emilua’s sandboxing relies on technologies that can isolate any code (e.g. C libraries to parse media streams). |
Back to our API, the hypothetical sandbox class that we showed earlier will
have to be some library that abstracts the differences between each sandbox
technology in the different platforms. The API that Emilua actually exposes as
of this release abstracts all of the semantics related to actor messaging,
work/lifetime accounting, process reaping, DoS protection, serialization, lots
of Linux namespaces details (e.g. PID1), and much more, but it still expects you
to actually initialize the sandbox.
The option linux_namespaces
The spawn_vm() function will only use Linux namespaces when you pass an
options object that instructs it to use Linux namespaces:
local my_channel = spawn_vm(module, { linux_namespaces = { ... } })The following options are supported for the linux_namespaces table:
new_uts: boolean = false-
Whether to create the process within a new UTS namespace.
new_ipc: boolean = false-
Whether to create the process within a new IPC namespace.
new_pid: boolean = false-
Whether to create the process within a new PID namespace.
new_user: boolean = false-
Whether to create the process within a new user namespace.
new_net: boolean = false-
Whether to create the process within a new net namespace.
new_mount: boolean = false-
Whether to create the process within a new mount namespace.
environment: { [string] = string }|nil-
A table of strings that will be used as the created process'
envp. Onnil, an emptyenvpwill be used. stdin,stdout,stderr: "share"|file_descriptor|nil-
"share"-
The spawned process will share the specified standard handle (
stdin,stdout, orstderr) with the caller process. file_descriptor-
Use the file descriptor as the specified standard handle (
stdin,stdout, orstderr) for the spawned process. nil-
Create and use a closed pipe end as the specified standard handle (
stdin,stdout, orstderr) for the spawned process.
init.script: string-
The source code for a script that is used to initialize the sandbox in the child process.
init.fd: file_descriptor-
A file descriptor that will be sent to the
init.script. The script can access this fd through the variablefdargthat is available within the script.
The init.script
Unless you execute the process as root, Linux will deny the creation of all namespaces except for the user namespace. The user namespace is the only namespace that an unprivileged process can create. However it’s fine to pair the user namespace with any combination of the other ones. Let’s start by isolating the network resources as that’s the easiest one:
spawn_vm('', {
linux_namespaces = {
new_user = true,
new_net = true
}
})The process will be created within a new network namespace where no interfaces
besides the loopback device exist. And even the loopback device will be down! If
you want to configure the loopback device so the process can at least bind
sockets to it you can use the program ip. However the program ip needs to
run within the new namespace. To spawn the program ip within the namespace of
the new actor you need to acquire the file descriptors to its namespaces. There
are two ways to do that. You can either use race-prone PID primitives (easy), or
you can use a handshake protocol to ensure that there are no races related to
PID dances. Below we show the race-free method.
local init_script = [[
local userns = C.open('/proc/self/ns/user', C.O_RDONLY)
send_with_fd(fdarg, '.', userns)
local netns = C.open('/proc/self/ns/net', C.O_RDONLY)
send_with_fd(fdarg, '.', netns)
-- sync point
C.read(fdarg, 1)
]]
local shost, sguest = unix.seqpacket_socket.pair()
sguest = sguest:release()
spawn_vm('', {
linux_namespaces = {
new_user = true,
new_net = true,
init = { script = init_script, fd = sguest }
}
})
sguest:close()
local ignored_buf = byte_span.new(1)
local userns = ({shost:receive_with_fds(ignored_buf, 1)})[2][1]
local netns = ({shost:receive_with_fds(ignored_buf, 1)})[2][1]
system.spawn{
program = 'ip',
arguments = {'ip', 'link', 'set', 'dev', 'lo', 'up'},
nsenter_user = userns,
nsenter_net = netns
}:wait()
shost:close()An AF_UNIX+SOCK_SEQPACKET socket is used to coordinate the parent and the
child processes. This type of socket allows duplex communication between two
parties with builtin framing for messages, disconnection detection (process
reference counting if you will), and it also allows sending file descriptors
back-and-forth.
errexitWe don’t want to accidentally ignore errors from the C API exposed to the
And |
We also close sguest from the host side as soon as we’re done with it. This
will ensure any operation on shost will fail if the child process aborts for
any reason (i.e. no deadlocks happen here).
If you for any reason absolutely need to use race-prone PID dances, you can access its numeric value by:
local my_channel = spawn_vm(...)
print(my_channel.child_pid)Do keep in mind that process reaping happens automatically and the PID won’t
remain reserved once the child dies, so it’s racy to use the PID. Even if
process reaping was not automatic, it’d still be possible to have races if the
parent died while some other process was using this PID. Use child_pid only as
a last resort.
|
The PID-dance race illustrated
One prevailing command in Linux distros today to assign an UID range to
unprivileged processes is the suid binary Unfortunately this idiom is race-prone. The PID of any target process is only
reserved until the parent process reaps it. If your program (and
This race is very unlikely to happen and not really dangerous on many use-cases,
but you should be aware of its existence. The same would apply to any PID dance
involving other tools (such as |
| You can use the same techniques taught here to initialize the UID/GID mapping for the user namespace. |
The PID namespace
When a new PID namespace is created, the process inside the new namespace ceases to see processes from the parent namespace. Your process still can see new processes created in the child’s namespace, so invisibility only happens in one direction. PID namespaces are hierarchically nested in parent-child relationships.
The first process in a PID namespace is PID1 within that namespace. PID1 has a
few special responsibilities. After the init.script exits, the Emilua runtime
will fork if it’s running as PID1. This new child will assume the role of
starting your module (the Lua VM). The PID1 process will perform the following
jobs:
-
Forward
SIGTERM,SIGUSR1,SIGUSR2,SIGHUP, andSIGINTto the child. There is no point in re-routing every signal, but more may be added to this set if you present a compelling case. -
Reap zombie processes.
-
Exit when the child dies with the same exit code as the child’s.
|
The controlling terminal
The Emilua runtime won’t call If you want to block the new actor from accessing the controlling terminal, you
may perform the usual calls in On the other hand, if you want to set up a pty in |
If the PID1 dies, all processes from that namespace (including further
descendant PID namespaces) will be killed. This behavior allows you to fully
dispose of a container when no longer needed by sending SIGKILL to PID1. No
process will escape.
Communication topology may be arbitrarily defined as per the actor model, but the processes always assume a topology of a tree (supervision trees), and no PID namespace ever “re-parents”.
The Emilua runtime automatically sends SIGKILL to every process spawned using
the Linux namespaces API when the actor that spawned them exits. If you want
fine control over these processes, you can use a few extra methods that are
available to the channel object that represents them.
The mount namespace
Let’s build up on our previous knowledge and build a sandbox with an empty "/"
(that’s right!).
local init_script = [[
...
-- unshare propagation events
C.mount(nil, '/', nil, C.MS_PRIVATE)
C.umask(0)
C.mount(nil, '/mnt', 'tmpfs', 0)
C.mkdir('/mnt/proc', mode(7, 5, 5))
C.mount(nil, '/mnt/proc', 'proc', 0)
C.mkdir('/mnt/tmp', mode(7, 7, 7))
-- pivot root
C.mkdir('/mnt/mnt', mode(7, 5, 5))
C.chdir('/mnt')
C.pivot_root('.', '/mnt/mnt')
C.chroot('.')
C.umount2('/mnt', C.MNT_DETACH)
-- sync point
C.read(fdarg, 1)
]]
spawn_vm('', {
linux_namespaces = {
...,
new_mount = true,
-- let's go ahead and create a new
-- PID namespace as well
new_pid = true
}
})We could certainly create a better initial "/". We could certainly do away
with a few of the lines by cleverly reordering them. However the example is
still nice to just illustrate a few of the syscalls exposed to the Lua
script. There’s nothing particularly hard about mount namespaces. We just call a
few syscalls, and no fd-dance between host and guest is really necessary.
|
Even if it’s a sandbox, and root inside the sandbox doesn’t mean root outside
it, maybe you still want to drop all root privileges at the end of the
It won’t be particularly useful for most people, but that technique is still useful to — for instance — create alternative LXC/FlatPak front-ends to run a few programs (if the program can’t update its own binary files, new possibilities for sandboxing practice open up). |
One technique that we should mention is how module in spawn_vm(module) is
interpreted when you use Linux namespaces. This argument no longer means an
actual module when namespaces are involved. It’ll just be passed along to the
new process. The following snippet shows you how to actually get the new actor
in the container by finding a proper module to start.
local guest_code = [[
local inbox = require 'inbox'
local ip = require 'ip'
local ch = inbox:receive().dest
ch:send(ip.host_name())
]]
local init_script = [[
...
local modulefd = C.open(
'/app.lua',
bit.bor(C.O_WRONLY, C.O_CREAT),
mode(6, 0, 0))
send_with_fd(fdarg, '.', modulefd)
]]
local my_channel = spawn_vm('/app.lua', ...)
...
local module = ({shost:receive_with_fds(ignored_buf, 1)})[2][1]
module = file.stream.new(module)
stream.write_all(module, guest_code)
shost:close()
my_channel:send{ dest = inbox }
print(inbox:receive())There’s a lot to comment on here. First: this setup is still hard! That’s no way a democratization of the sandboxing technology that was promised in the beginning of this text. However, do keep in mind that all of this is just for setup and almost all of that can be abstracted away in a library. Once all that is abstracted away, pay attention to all benefits you get:
-
The channel API from the actor model work just the same. Arbitrary topology, work-counting tracking to abort a read operation when supervisor subtrees die and some process becomes unreachable, object serialization, and plenty more. All that works per usual.
-
The only resources a process has access to are the resources that are explicitly given to it. Pay close attention that the child process couldn’t even send its host name back to the parent without the parent first sending its address over. The parent could just as well create another actor to just supervise this sandbox and not send its address directly. All usual properties from capability-based security systems follow.
-
The system is dynamic and now you can create new sandboxes on demand (think of each sandbox as a new user in the system isolated from each other). For a web browser, one valid strategy would be to spawn a sandbox for each tab in the UI. That’s one property not easily achievable (or even possible) with many of the security solutions that are common today (e.g. SELinux). Please read the Capsicum paper to get more on this point.
-
Should the need arise, you retain low level controls over the container setup. That should give the API applicability beyond application compartmentalisation. Now you can build your own front-ends for the application trees shared by FlatPak, LXC, and other container projects.
Now to the problems: as it stands, it’s impossible to build automatic support to share modules between the host and the sandboxes. The Capsicum project faced a similar problem in C and had to customize the loader. A library cannot abstract this problem. The Emilua project needs a package manager to tackle it, and that will be one of its next milestones. Once we’re there, then the promise of democratizing this technology could be fulfilled.
Full example
local stream = require 'stream'
local system = require 'system'
local inbox = require 'inbox'
local file = require 'file'
local unix = require 'unix'
local guest_code = [[
local inbox = require 'inbox'
local ip = require 'ip'
local ch = inbox:receive().dest
ch:send(ip.host_name())
]]
local init_script = [[
local uidmap = C.open('/proc/self/uid_map', C.O_WRONLY)
send_with_fd(fdarg, '.', uidmap)
C.write(C.open('/proc/self/setgroups', C.O_WRONLY), 'deny')
local gidmap = C.open('/proc/self/gid_map', C.O_WRONLY)
send_with_fd(fdarg, '.', gidmap)
-- sync point #1 as tmpfs will fail on mkdir()
-- with EOVERFLOW if no UID/GID mapping exists
-- https://bugzilla.kernel.org/show_bug.cgi?id=183461
C.read(fdarg, 1)
local userns = C.open('/proc/self/ns/user', C.O_RDONLY)
send_with_fd(fdarg, '.', userns)
local netns = C.open('/proc/self/ns/net', C.O_RDONLY)
send_with_fd(fdarg, '.', netns)
-- unshare propagation events
C.mount(nil, '/', nil, C.MS_PRIVATE)
C.umask(0)
C.mount(nil, '/mnt', 'tmpfs', 0)
C.mkdir('/mnt/proc', mode(7, 5, 5))
C.mount(nil, '/mnt/proc', 'proc', 0)
C.mkdir('/mnt/tmp', mode(7, 7, 7))
-- pivot root
C.mkdir('/mnt/mnt', mode(7, 5, 5))
C.chdir('/mnt')
C.pivot_root('.', '/mnt/mnt')
C.chroot('.')
C.umount2('/mnt', C.MNT_DETACH)
local modulefd = C.open(
'/app.lua',
bit.bor(C.O_WRONLY, C.O_CREAT),
mode(6, 0, 0))
send_with_fd(fdarg, '.', modulefd)
-- sync point #2 as we must await for
--
-- * loopback net device
-- * `/app.lua`
--
-- before we run the guest
C.read(fdarg, 1)
C.sethostname('mycoolhostname')
C.setdomainname('mycooldomainname')
-- drop all root privileges
C.cap_set_proc('=')
]]
local shost, sguest = unix.seqpacket_socket.pair()
sguest = sguest:release()
local my_channel = spawn_vm('/app.lua', {
linux_namespaces = {
new_user = true,
new_net = true,
new_mount = true,
new_pid = true,
new_uts = true,
new_ipc = true,
init = { script = init_script, fd = sguest }
}
})
sguest:close()
local ignored_buf = byte_span.new(1)
local uidmap = ({system.getresuid()})[2]
uidmap = byte_span.append('0 ', tostring(uidmap), ' 1\n')
local uidmapfd = ({shost:receive_with_fds(ignored_buf, 1)})[2][1]
file.stream.new(uidmapfd):write_some(uidmap)
local gidmap = ({system.getresgid()})[2]
gidmap = byte_span.append('0 ', tostring(gidmap), ' 1\n')
local gidmapfd = ({shost:receive_with_fds(ignored_buf, 1)})[2][1]
file.stream.new(gidmapfd):write_some(gidmap)
-- sync point #1
shost:send(ignored_buf)
local userns = ({shost:receive_with_fds(ignored_buf, 1)})[2][1]
local netns = ({shost:receive_with_fds(ignored_buf, 1)})[2][1]
system.spawn{
program = 'ip',
arguments = {'ip', 'link', 'set', 'dev', 'lo', 'up'},
nsenter_user = userns,
nsenter_net = netns
}:wait()
local module = ({shost:receive_with_fds(ignored_buf, 1)})[2][1]
module = file.stream.new(module)
stream.write_all(module, guest_code)
-- sync point #2
shost:close()
my_channel:send{ dest = inbox }
print(inbox:receive())Implementation details
| The purpose of this section is to help you attack the system. If you’re trying to find security holes, this section should be a good overview on how the whole system works. |
If you find any bug in the code, please responsibly send a bug report so the Emilua team can fix it.
Message serialization
Emilua follows the advice from WireGuard developers to avoid parsing bugs by avoiding object serialization altogether. Sequenced-packet sockets with builtin framing are used so we always receive/send whole messages in one API call.
There is a hard-limit (configurable at build time) on the maximum number of members you can send per message. This limit would need to exist anyway to avoid DoS from bad clients.
Another limitation is that no nesting is allowed. You can either send a single non-nil value or a non-empty dictionary where every member in it is a leaf from the root tree. The messaging API is part of the attack surface that bad clients can exploit. We cannot afford a single bug here, so the code must be simple. By forbidding subtrees we can ignore recursion complexities and simplify the code a lot.
The struct used to receive messages follows:
enum kind
{
boolean_true = 1,
boolean_false = 2,
string = 3,
file_descriptor = 4,
actor_address = 5,
nil = 6
};
struct linux_container_message
{
union
{
double as_double;
uint64_t as_int;
} members[EMILUA_CONFIG_LINUX_NAMESPACES_MESSAGE_MAX_MEMBERS_NUMBER];
unsigned char strbuf[
EMILUA_CONFIG_LINUX_NAMESPACES_MESSAGE_SIZE - sizeof(members)];
};A variant class is needed to send the messages. Given a variant is needed anyway, we just adopt NaN-tagging for its implementation as that will make the struct members packed together and no memory from the host process hidden among paddings will leak to the containers.
The code assumes that no signaling NaNs are ever produced by the Lua VM to simplify the NaN-tagging scheme[2][3]. The type is stored in the mantissa bits of a signaling NaN.
If the first member is nil, then we have a non-dictionary value stored in
members[1]. Otherwise, a nil will act as a sentinel to the end of the
dictionary. No sentinel will exist when the dictionary is fully filled.
read() calls will write to objects of this type directly (i.e. no intermediate
char[N] buffer is used) so we avoid any complexity with code related to
alignment adjustments.
memset(buf, 0, s) is used to clear any unused member of the struct before a
call to write() so we avoid leaking memory from the process to any container.
Strings are preceded by a single byte that contains the size of the string that follows. Therefore, strings are limited to 255 characters. Following from this scheme, a buffer sufficiently large to hold the largest message is declared to avoid any buffer overflow. However, we still perform bounds checking to make sure no uninitialized data from the code stack is propagated back to Lua code to avoid leaking any memory. The bounds checking function in the code has a simple implementation that doesn’t make the code much more complex and it’s easy to follow.
To send file descriptors over, SCM_RIGHTS is used. There are a lot of quirks
involved with SCM_RIGHTS (e.g. extra file descriptors could be stuffed into
the buffer even if you didn’t expect them). The encoding scheme for the network
buffer is far simpler to use than SCM_RIGHTS' ancillary
data. Complexity-wise, there’s far greater chance to introduce a bug in code
related to SCM_RIGHTS than a bug in the code that parses the network buffer.
Code could be simpler if we only supported messaging strings over, but that would just defer the problem of secure serialization on the user’s back. Code should be simple, but not simpler. By throwing all complexity on the user’s back, the implementation would offer no security. At least we centralized the sensitive object serialization so only one block of code need to be reviewed and audited.
Spawning a new process
UNIX systems allow the userspace to spawn new processes by a fork() followed
by an exec(). exec() really means an executable will be available in the
container, but this assumption doesn’t play nice with our idea of spawning new
actors in an empty container.
What we really want is to to perform a fork followed by no exec() call. This
approach in itself also has its own problems. exec() is the only call that
will flush the address space of the running process. If we don’t exec() then
the new process that was supposed to run untrusted code with no access to system
resources will be able to read all previous memory — memory that will most
likely contain sensitive information that we didn’t want leaked. Other problems
such as threads (supported by the Emilua runtime) would also hinder our ability
to use fork() without exec()ing.
One simple approach to solve all these problems is to fork() at the beginning
of the program so we fork() before any sensitive information is loaded in the
process' memory. Forking at a well known point also brings other benefits. We
know that no thread has been created yet, so resources such as locks and the
global memory allocator stay in a well defined state. By creating this extra
process before much more extra virtual memory or file descriptor slots in our
process table have been requested, we also make sure that further processes
creation will be cheaper.
└─ emilua program
└─ emilua runtime (supervisor fork()ed near main())Every time the main process wants to create an actor in a new process, it’ll
defer its job onto the supervisor that was fork()ed near main(). An
AF_UNIX+SOCK_SEQPACKET socket is used to orchestrate this process. Given the
supervisor is only used to create new processes, it can use blocking APIs that
will simplify the code a lot. The blocking read() on the socket also means
that it won’t be draining any CPU resources when it’s not needed. Also important
is the threat model here. The main process is not trying to attack the
supervisor process. The supervisor is also trusted and it doesn’t need to run
inside a container. SCM_RIGHTS handling between the main process and the
supervisor is simplified a lot due to these constraints.
However some care is still needed to setup the supervisor. Each actor will
initially be an exact copy of the supervisor process memory and we want to make
sure that no sensitive data is leaked there. The first thing we do right after
creating the supervisor is collecting any sensitive information that might still
exist in the main process (e.g. argv and envp) and instructing the
supervisor process to explicit_bzero() them. This compromise is not as good as
exec() would offer, but it’s the best we can do while we limit ourselves to
reasonably portable C code with few assumptions about dynamic/static linkage
against system libraries, and other settings from the host environment.
This problem doesn’t end here. Now that we assume the process memory from the
supervisor contains no sensitive data, we want to keep it that way. It may be
true that every container is assumed as a container that some hacker already
took over (that’s why we’re isolating them, after all), but one container
shouldn’t leak information to another one. In other words, we don’t even want to
load sensitive information regarding the setup of any container from the
supervisor process as that could leak into future containers. The solution here
is to serialize such information (e.g. the init.script) such that it is only
sent directly to the final process. Another AF_UNIX+SOCK_SEQPACKET socket is
used.
Now to the assumptions on the container process. We do assume that it’ll run
code that is potentially dangerous and some hacker might own the container at
some point. However the initial setup does not run arbitrary dangerous code
and it still is part of the trusted computing base. The problem is that we don’t
know whether the init.script will need to load sensitive information at any
point to perform its job. That’s why we setup the Lua VM that runs init.script
to use a custom allocator that will explicit_bzero() all allocated memory at
the end. Allocations done by external libraries such as libcap lie outside of
our control, but they rarely matter anyway.
That’s mostly the bulk of our problems and how we handle them. Other problems are summarized in the short list below.
-
SIGCHLDwould be sent to the main process, but we cannot install arbitrary signal handlers in the main process as that’s a property from the application (i.e. signal handling disposition is not a resource owned by the Emilua runtime). The problem was already solved by making the actor a child of the supervisor process. -
We can’t install arbitrary signal handlers in the container process either as that would break every module by bringing different semantics depending on the context where it runs (host/container). To handle PID1 automatically we just fork a new process and forward its signals to the new child.
-
"/proc/self/exe"is a resource inherited from the main process (i.e. a resource that exists outside the container, so the container is not existing in a completely empty world), and could be exploited in the container.ETXTBSYwill hinder the ability from the container to meddle with"/proc/self/exe", andETXTBSYis guaranteed by the existence of the supervisor process (even if the main process exits, the supervisor will stay alive).
The output from tools such as top start to become rather cool when you play
with nested containers:
└─ emilua program
└─ emilua runtime (supervisor fork()ed near main())
├─ emilua runtime (PID1 within the new namespace)
│ └─ emilua program
│ └─ emilua runtime (supervisor fork()ed near main())
└─ emilua runtime (PID1 within the new namespace)
└─ emilua program
└─ emilua runtime (supervisor fork()ed near main())Work lifetime management
PID1 eases our life a lot. As soon as any container starts to act suspiciously
we can safely kill the whole subtree of processes by sending SIGKILL to the
PID1 that started it.
AF_UNIX+SOCK_SEQPACKET sockets are connection-oriented and simplify our work
even further. We shutdown() the ends of each pair such that they’ll act
unidirectionally just like pipes. When all copies of one end die, the operation
on the other end will abort. The actor API translates to MPSC channels, so we
never ever send the reading end to any container (we only make copies of the
sending end). The kernel will take care of any tricky reference counting
necessary (and SIGKILLing PID1 will make sure no unwanted end survives).
The only work left for us to do is pretty much to just orchestrate the internal
concurrency architecture of the runtime (e.g. watch out for blocking
reads). Given that we want to abort reads when all the copies of the sending end
are destroyed, we don’t keep any copy to the sending end in our own
process. Everytime we need to send our address over, we create a new pair of
sockets to send the newly created sending end over. inbox will unify the
receipt of messages coming from any of these sockets. You can think of each
newly created socket as a new capability. If one capability is revoked, others
remain unaffected.
One good actor could send our address further to a bad actor, and there is no
way to revoke access to the bad actor without also revoking access to the good
actor, but that is in line with capability-based security systems. Access rights
are transitive. In fact, a bad actor could write 0-sized messages over the
AF_UNIX+SOCK_SEQPACKET socket to trick us into thinking the channel was
already closed. We’ll happily close the channel and there is no problem
here. The system can happily recover later on (and only this capability is
revoked anyway).
Flow control
The runtime doesn’t schedule any read on the socket unless the user calls
inbox:receive(). Upon reading a new message the runtime will either wake the
receiving fiber directly, or enqueue the result in a buffer if no receiving
fiber exists at the time (this can happen if the user interrupted the fiber, or
another result arrived and woke the fiber up already). inbox:receive() won’t
schedule any read on the socket if there’s some result already enqueued in the
buffer.
setns(fd, CLONE_NEWPID)
We don’t offer any helper to spawn a program (i.e. system.spawn()) within an
existing PID namespace. That’s intentional (although one could still do it
through init.script). setns(fd, CLONE_NEWPID) is dangerous. Only exec()
will flush the address space for the process. The window of time that exists
until exec() is called means that any memory from the previous process could
be read by a compromised container (cf. ptrace(2)).
Tests
A mix of approaches is used to test the implementation.
There’s an unit test for every class of good inputs. There are unit tests for accidental bad inputs that one might try to perform through the Lua API. The unit tests always try to create one scenario for buffered messages and another for immediate delivery of the result.
When support for plugins is enabled, fuzz tests are built as well. The fuzzers are generation-based. One fuzzer will generate good input and test if the program will accept all of them. Another fuzzer will mutate a good input into a bad one (e.g. truncate the message size to attempt a buffer overflow), and check if the program rejects all of them.
There are some other tests as well (e.g. ensure no padding exists between the members of the C struct we send over the wire).
The C API exposed to init.script
Helpers
mode(user: integer, group: integer, other: integer) → integer
function mode(user, group, other)
return bit.bor(bit.lshift(user, 6), bit.lshift(group, 3), other)
endFunctions
These functions live inside the global table C. errno (or 0 on success) is
returned as the second result.
-
read(). Opposed to the C function, it receives two arguments. The second argument is the size of the buffer. The buffer is allocated automatically, and returned as a string in the first result (unless an error happens, thennilis returned). -
write(). Opposed to the C function, it receives two arguments. The second one is a string which will be used as the buffer. -
sethostname(). Opposed to the C function, it only receives the string argument. -
setdomainname(). Opposed to the C function, it only receives the string argument. -
setgroups(). Opposed to the C function, it receives a list of numbers as its single argument. -
cap_set_proc(). Opposed to the C function, it receives a string as its single argument. The string is converted to thecap_ttype using the functioncap_from_text(). -
cap_drop_bound(). Opposed to the C function, it receives a string as its single argument. The string is converted to thecap_value_ttype using the functioncap_from_name(). -
cap_set_ambient(). Opposed to the C function, it receives a string as its first argument. The string is converted to thecap_value_ttype using the functioncap_from_name(). The second parameter is a boolean. -
execve(). Opposed to the C function,argvandenvpare specified as a Lua table. -
fexecve(). Opposed to the C function,argvandenvpare specified as a Lua table.
Other exported functions work as usual (except that errno or 0 is returned
as the second result):
-
open(). -
mkdir(). -
chdir(). -
umask(). -
mount(). -
umount(). -
umount2(). -
pivot_root(). -
chroot(). -
setsid(). -
setpgid(). -
setresuid(). -
setresgid(). -
cap_reset_ambient(). -
cap_set_secbits(). -
unshare(). -
setns().
Constants
These constants live inside the global table C.
-
O_CLOEXEC. -
EAFNOSUPPORT. -
EADDRINUSE. -
EADDRNOTAVAIL. -
EISCONN. -
E2BIG. -
EDOM. -
EFAULT. -
EBADF. -
EBADMSG. -
EPIPE. -
ECONNABORTED. -
EALREADY. -
ECONNREFUSED. -
ECONNRESET. -
EXDEV. -
EDESTADDRREQ. -
EBUSY. -
ENOTEMPTY. -
ENOEXEC. -
EEXIST. -
EFBIG. -
ENAMETOOLONG. -
ENOSYS. -
EHOSTUNREACH. -
EIDRM. -
EILSEQ. -
ENOTTY. -
EINTR. -
EINVAL. -
ESPIPE. -
EIO. -
EISDIR. -
EMSGSIZE. -
ENETDOWN. -
ENETRESET. -
ENETUNREACH. -
ENOBUFS. -
ECHILD. -
ENOLINK. -
ENOLCK. -
ENODATA. -
ENOMSG. -
ENOPROTOOPT. -
ENOSPC. -
ENOSR. -
ENXIO. -
ENODEV. -
ENOENT. -
ESRCH. -
ENOTDIR. -
ENOTSOCK. -
ENOSTR. -
ENOTCONN. -
ENOMEM. -
ENOTSUP. -
ECANCELED. -
EINPROGRESS. -
EPERM. -
EOPNOTSUPP. -
EWOULDBLOCK. -
EOWNERDEAD. -
EACCES. -
EPROTO. -
EPROTONOSUPPORT. -
EROFS. -
EDEADLK. -
EAGAIN. -
ERANGE. -
ENOTRECOVERABLE. -
ETIME. -
ETXTBSY. -
ETIMEDOUT. -
ENFILE. -
EMFILE. -
EMLINK. -
ELOOP. -
EOVERFLOW. -
EPROTOTYPE. -
O_CREAT. -
O_RDONLY. -
O_WRONLY. -
O_RDWR. -
O_DIRECTORY. -
O_EXCL. -
O_NOCTTY. -
O_NOFOLLOW. -
O_TMPFILE. -
O_TRUNC. -
O_APPEND. -
O_ASYNC. -
O_DIRECT. -
O_DSYNC. -
O_LARGEFILE. -
O_NOATIME. -
O_NONBLOCK. -
O_PATH. -
O_SYNC. -
S_IRWXU. -
S_IRUSR. -
S_IWUSR. -
S_IXUSR. -
S_IRWXG. -
S_IRGRP. -
S_IWGRP. -
S_IXGRP. -
S_IRWXO. -
S_IROTH. -
S_IWOTH. -
S_IXOTH. -
S_ISUID. -
S_ISGID. -
S_ISVTX. -
MS_REMOUNT. -
MS_BIND. -
MS_SHARED. -
MS_PRIVATE. -
MS_SLAVE. -
MS_UNBINDABLE. -
MS_MOVE. -
MS_DIRSYNC. -
MS_LAZYTIME. -
MS_MANDLOCK. -
MS_NOATIME. -
MS_NODEV. -
MS_NODIRATIME. -
MS_NOEXEC. -
MS_NOSUID. -
MS_RDONLY. -
MS_REC. -
MS_RELATIME. -
MS_SILENT. -
MS_STRICTATIME. -
MS_SYNCHRONOUS. -
MS_NOSYMFOLLOW. -
MNT_FORCE. -
MNT_DETACH. -
MNT_EXPIRE. -
UMOUNT_NOFOLLOW. -
CLONE_NEWCGROUP. -
CLONE_NEWIPC. -
CLONE_NEWNET. -
CLONE_NEWNS. -
CLONE_NEWPID. -
CLONE_NEWTIME. -
CLONE_NEWUSER. -
CLONE_NEWUTS. -
SECBIT_NOROOT. -
SECBIT_NOROOT_LOCKED. -
SECBIT_NO_SETUID_FIXUP. -
SECBIT_NO_SETUID_FIXUP_LOCKED. -
SECBIT_KEEP_CAPS. -
SECBIT_KEEP_CAPS_LOCKED. -
SECBIT_NO_CAP_AMBIENT_RAISE. -
SECBIT_NO_CAP_AMBIENT_RAISE_LOCKED.